
In this tutorial, we’ll walk through setting up a FastAPI project designed for Machine Learning Operations (MLOps). This guide covers everything from project structure organization to automated deployment using GitHub Actions. Along the way, we’ll use Poetry for streamlined dependency management and Docker to simplify deployment. Whether your goal is to make your models more reproducible, streamline workflows, or establish a smooth deployment pipeline, this guide will provide a solid foundation for taking machine learning models into homologation.
Note: This tutorial is specifically for creating microservices that deploy models rapidly for homologation use. The GitHub repository link for this app is at the end, but if you’re new to setting up ML services, we recommend following the entire tutorial for a thorough understanding.
Prerequisites
Ensure you have these installed before starting:
- Python for building and running the application.
- Docker for containerization and deployment.
- Poetry to manage dependencies.
- AWS Account for deployment.
- GitHub Actions (optional) for CI/CD automation.
Project Layout and Poetry Setup
To build a robust ML application, we’ll start by structuring the project and setting up Poetry as our dependency manager. This tool simplifies environment setup and keeps your project aligned with modern packaging standards.
Create the Project Structure
First, create a project directory and set up the following folder structure:
mlops-fastapi-microservice/
├── .github/
│ └── workflows/
│ └── deploy.yml
├── src/
│ ├── api/
│ │ └── v1/
│ │ └── routes.py
│ ├── core/
│ │ ├── config.py
│ │ ├── database.py
│ │ └── server.py
│ ├── app/
│ │ ├── repositories/
│ │ ├── schemas/
│ │ ├── services/
│ │ │ └── model_service.py
│ └── middleware/
├── tests/
│ ├── test_api.py
│ └── test_services.py
├── models/
│ └── model.pkl
├── .gitignore
├── docker-compose.yaml
├── Dockerfile
├── LICENSE
├── pyproject.toml
├── README.md
└── train_model.pyEach folder serves a specific purpose:
- .github/: Holds Github Actions pipeline
- src/: Contains the application source code.
- tests/: Holds unit tests.
- models/: Holds the ML models.
- pyproject.toml: Configuration file for Poetry.
Why Use Poetry?
Poetry manages dependencies through pyproject.toml, providing consistency across environments and handling virtual environments automatically. It simplifies project initialization and packaging, adhering to PEP 517 standards.
Install Poetry
If you haven’t installed Poetry, use:
pip install poetryInitialize the Project with Poetry
Navigate to your project directory and initialize it with Poetry:
mkdir mlops-fastapi-microservice && cd mlops-fastapi-microservice
poetry initThis command will guide you through setting up the pyproject.toml file.
Add Dependencies
Now, add essential dependencies like FastAPI, Uvicorn, and ML-related libraries:
poetry add fastapi uvicorn pandas scikit-learn joblib pydantic python-dotenv pytest databases httpx aiosqliteYour pyproject.toml should look like this:
[tool.poetry]
name = "mlops-fastapi-microservice"
version = "0.1.0"
description = ""
authors = ["Ives Furtado <ivesfurtado@yahoo.com>"]
readme = "README.md"
[tool.poetry.dependencies]
python = "^3.12"
fastapi = "^0.115.4"
uvicorn = "^0.32.0"
pandas = "^2.2.3"
scikit-learn = "^1.5.2"
joblib = "^1.4.2"
pydantic = "^2.9.2"
python-dotenv = "^1.0.1"
pytest = "^8.3.3"
httpx = "^0.27.2"
databases = "^0.9.0"
aiosqlite = "^0.20.0"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
Add a .gitignore file.
# Python
__pycache__/
*.py[cod]
*.pyo
*.pyd
*.env
.env
# Poetry
poetry.lock
.cache/
virtualenvs/
# Docker
*.log
*.pid
*.sock
*.env
# Models
models/*.pkl
# Jupyter Notebooks
.ipynb_checkpoints/
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
*.cover
coverage.xml
*.log
nosetests.xml
coverage/
# GitHub Actions
.github/workflows/*.log
# Temporary files
*.tmp
*.temp
*.swp
*.swo
.python-version
# MacOS
.DS_Store
# AWS EC2 key files (if applicable)
*.pem
Setting Up server.py
Now, let’s create a basic FastAPI server in src/core/server.py:
# src/core/server.py
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"message": "Hello, FastAPI!"}
This code initializes a FastAPI app instance and defines a root endpoint ("/") that returns a JSON message.
Run Your Application
With everything set up, you can now start your FastAPI application by running:
poetry run uvicorn src.core.server:app --reloadOpen your browser at http://127.0.0.1:8000, and you should see the message:
{"message": "Hello, FastAPI!"}Training the Model
In this step we will create a python file anywhere just to train the test model we’re going to set up in our application. Create a script to train and save the model in train_model.py:
# train_model.py
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import joblib
import os
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = RandomForestClassifier()
model.fit(X_train, y_train)
if not os.path.exists("models"):
os.makedirs("models")
joblib.dump(model, "models/model.pkl")
Run this script to train and save the model:
poetry run python -m train_modelConfiguration Management with config.py
In this project, config.py holds configuration values such as database URLs and model paths, making it easy to adjust settings without modifying code. Place it in src/core/:
# src/core/config.py
import os
from dotenv import load_dotenv
load_dotenv()
class Settings:
MODEL_PATH: str = os.getenv("MODEL_PATH", "models/model.pkl")
DEBUG: bool = os.getenv("DEBUG", "false").lower() == "true"
settings = Settings()
This configuration file uses environment variables to keep sensitive information, like database credentials, secure and flexible for different environments. Use this settings instance to access configuration values in other parts of the application.
Business Logic Separation
When building an ML application, it’s essential to separate business logic for scalability and maintainability. This setup ensures that model handling logic is isolated from other application components.
In this project, model_service.py will contain the logic for loading and running predictions using your machine learning models. Place this file within the services directory under src/app/:
mlops-fastapi-microservice/
├── src/
│ ├── app/
│ │ ├── services/
│ │ │ ├── __init__.py
│ │ │ └── model_service.py
│ └── core/
├── docs/
├── pyproject.toml
├── poetry.lock
├── Dockerfile
├── docker-compose.yaml
└── README.md
Here’s how to implement the service in model_service.py:
# src/app/services/model_service.py
import joblib
import pandas as pd
from pydantic import BaseModel
from src.core.config import settings
class PredictionInput(BaseModel):
features: dict
class PredictionService:
def __init__(self):
self.model = joblib.load(settings.MODEL_PATH)
def predict(self, input_data: PredictionInput):
df = pd.DataFrame([input_data.features])
return self.model.predict(df)
This PredictionService class encapsulates the model loading and prediction logic, making it easier to test and maintain.
Model Serving with FastAPI
Since we’re not using an MLFlow server, FastAPI will serve as the primary interface for model predictions.
Set up a Prediction Route
In src/api/v1/routes.py, set up a route that receives requests, runs predictions, and returns the result.
# src/api/v1/routes.py
from fastapi import APIRouter, Depends
from src.app.services.model_service import PredictionInput, PredictionService
router = APIRouter()
@router.post("/predict")
async def predict(input_data: PredictionInput, service: PredictionService = Depends()):
prediction = service.predict(input_data)
return {"prediction": prediction.tolist()}
Now let’s update our src/core/server.py file to add the new routes.
# src/core/server.py
from fastapi import FastAPI
from contextlib import asynccontextmanager
from src.api.v1.routes import router as prediction_router
app = FastAPI()
# Include the prediction router
app.include_router(prediction_router, prefix="/api/v1")
@app.get("/")
def read_root():
return {"message": "Hello, FastAPI!"}
Testing with Sample Data
Let’s test our prediction endpoint using sample data. You can use curl or any HTTP client like Postman to send requests.
Example request using curl:
curl -X POST "http://127.0.0.1:8000/api/v1/predict" -H "Content-Type: application/json" -d '{"features": {"sepal length (cm)": 5.1, "sepal width (cm)": 3.5, "petal length (cm)": 1.4, "petal width (cm)": 0.2}}'Expected response:
{
"prediction": [0]
}This means that our model predicted class 0 for this input data.
Writing Unit Tests for API and Services
Testing is crucial for ensuring that your API works as expected. Let’s write some unit tests for both the API endpoints and services.
Writing Unit Tests for API (test_api.py)
In tests/test_api.py, create tests for the prediction endpoint using FastAPI’s test client:
# tests/test_api.py
from fastapi.testclient import TestClient
from src.core.server import app
client = TestClient(app)
def test_read_root():
response = client.get("/")
assert response.status_code == 200
assert response.json() == {"message": "Hello, FastAPI!"}
def test_predict():
response = client.post(
"/api/v1/predict",
json={"features": {"sepal length (cm)": 5.1, "sepal width (cm)": 3.5, "petal length (cm)": 1.4, "petal width (cm)": 0.2}}
)
assert response.status_code == 200
assert "prediction" in response.json()
Writing Unit Tests for Services (test_services.py)
In tests/test_services.py, write tests for the prediction service logic:
# tests/test_services.py
from src.app.services.model_service import PredictionService, PredictionInput
def test_prediction_service():
service = PredictionService()
input_data = PredictionInput(features={"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2})
prediction = service.predict(input_data)
assert len(prediction) == 1 # Ensure one prediction is returned.
Running Unit Tests
Run all tests using pytest:
poetry run python -m pytest tests/This will execute all test cases in both test_api.py and test_services.py.
Docker Configuration for Deployment
To create a portable and reproducible environment, set up a Dockerfile:
# Dockerfile
FROM python:3.12-slim
WORKDIR /app
COPY ./src /app/src
COPY pyproject.toml poetry.lock /app/
RUN pip install poetry && \
poetry config virtualenvs.create false && \
poetry install --no-dev
EXPOSE 8000
CMD ["uvicorn", "src.core.server:app", "--host=0.0.0.0", "--port=8000"]
This Dockerfile ensures that Poetry is used to install dependencies within the container, keeping your environment consistent.
To manage environment variables and run dependencies, use docker-compose.yaml:
version: '3.8'
services:
fastapi-service:
build: .
ports:
- "8000:8000"
environment:
- MODEL_PATH=/app/models/model.pkl
Building and Running Your Docker Container
To build and run your application:
Build the Docker Image:
docker build -t mlops-fastapi-microservice:latest .Run the Docker Container:
docker run -p 80:80 mlops-fastapi-microservice:latestCI/CD Pipeline with GitHub Actions for MLOPS
To automate your deployment:
- Create an EC2 instance (in this tutorial I’m using t4g.nano, if you’re going to use another instance/architecture, please edit the file below to account for this change) and add Docker/Docker Compose
- Create a
.github/workflowsdirectory in your project root. - Add a workflow file (e.g.,
deploy.yml):
name: Deploy FastAPI to AWS EC2
on:
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-latest
environment: prod
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.12'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install poetry
poetry install --no-dev
- name: Run tests
run: |
poetry run python -m pytest tests/
- name: Login to Docker Hub
uses: docker/login-action@v2
with:
username: ${{ secrets.DOCKER_USERNAME }}
password: ${{ secrets.DOCKER_PASSWORD }}
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v2
- name: Build and push multi-platform Docker image
uses: docker/build-push-action@v2
with:
push: true
platforms: linux/arm64/v8
tags: ivesfurtado/mlops-fastapi-microservice:latest
- name: Deploy to AWS EC2
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
run: |
echo "${{ secrets.EC2_SSH_KEY }}" > /tmp/mlops-fastapi-microservice.pem
chmod 600 /tmp/mlops-fastapi-microservice.pem
ssh -o StrictHostKeyChecking=no -i /tmp/mlops-fastapi-microservice.pem ec2-user@${{ secrets.EC2_IP }} '
sudo yum update -y &&
docker pull ivesfurtado/mlops-fastapi-microservice:latest &&
docker stop $(docker ps -a -q) || true &&
docker run -d -p 80:80 ivesfurtado/mlops-fastapi-microservice:latest
'
- name: Clean up SSH key
run: |
rm /tmp/mlops-fastapi-microservice.pem
This workflow automates testing, building Docker images, and deploying to AWS EC2.
Important Note: Set Up GitHub Secrets
To ensure the workflow runs smoothly, you must set up the following secrets in your GitHub repository:
- DOCKER_USERNAME: Your Docker Hub username.
- DOCKER_PASSWORD: Your Docker Hub password or access token.
- AWS_ACCESS_KEY_ID: Your AWS IAM Access Key ID with permissions to manage EC2 instances.
- AWS_SECRET_ACCESS_KEY: Your AWS IAM Secret Access Key.
- EC2_SSH_KEY: The private SSH key used to connect to the EC2 instance.
- EC2_IP: The public IP address of your EC2 instance.
To set up these secrets:
- Navigate to your repository on GitHub.
- Go to Settings > Secrets and variables > Actions.
- Click New repository secret for each of the above values.
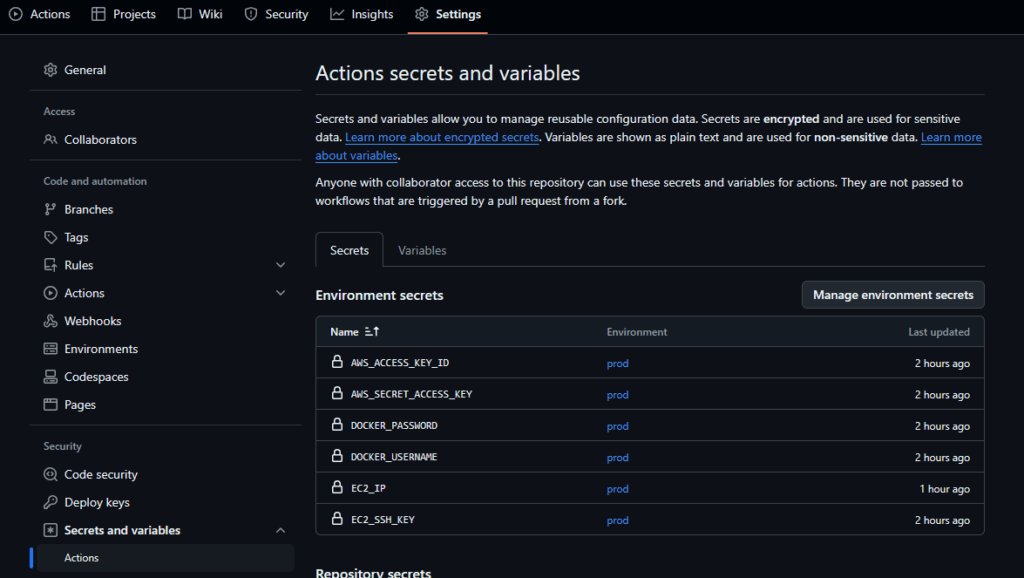
Here’s how my repository secrets are set up. Pay attention to the environment name you configure here and in the deploy file:
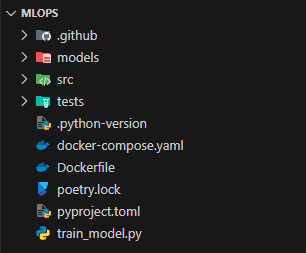
Now your working directory should look like this:
After setting up your secrets and deploying your app, access the EC2 public IP, and you will see the following:

Conclusion
By following this guide, you’ve established a FastAPI-based MLOps project with dependency management via Poetry and containerization using Docker. You’ve also implemented a prediction-serving API endpoint, tested with sample data. This setup is highly customizable, allowing you to deploy locally or on cloud services like AWS or GCP, ensuring that your machine learning models are homologation-ready and scalable. Enhance this by adding security features, retries, and other improvements to make it production-ready!
Visit the repository and leave a star 👉 github.com/ivesfurtado/mlops-fastapi-microservice
Leave a Reply